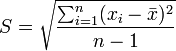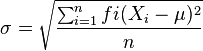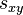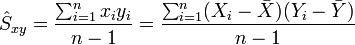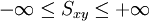ELEMENTOS DE UNA GRÁFICA:
En general se deben tener en cuenta los siguientes elementos:
1.Titulo
2.Tabla o Distribución de Frecuencias
3.Escala
4.Cuerpo de la gráfica
5.Convenciones
6.Notas aclaratorias
7.Numeración.
DIAGRAMA CIRCULAR
Es de especial utilidad para mostrar proporciones (porcentajes) relativas de una variable. Se crea marcando una porción del círculo correspondiente a cada categoría de la variable .
GRÁFICA SIMPLE DE BARRAS VERTICALES
Para respuestas categóricas cualitativas en el que solo interviene una barra para cada clase. Su trazo se realiza ubicando en el eje horizontal de la gráfica los nombres que identifican cada una de las clases. En el eje vertical se usa una escala de frecuencias, una de frecuencias relativas o una de porcentuales. Luego, con una barra de un ancho fijo trazada sobre cada indicador de clase llegamos a la altura que corresponde al tipo de frecuencia escogido. Las barras se separan a fin de señalar que cada clase es una categoría independiente. Los espacios entre las barras deben corresponder a la mitad del ancho de una barra.

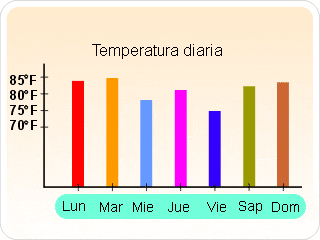
GRÁFICA SIMPLE DE BARRAS HORIZONTALES
Se utiliza principalmente para facilitar la comparación entre las diferentes clases que componen los datos categóricos. El trazo de la gráfica es muy similar a la gráfica de barras verticales, solo que éstas van en forma horizontal y están ordenadas de la mayor a la menor frecuencia absolutas, de frecuencia relativas o de porcentajes. De esta manera se logra una mejor visualización en las preferencias.
HISTOGRAMAS
Una de las maneras más comunes de representar una distribución de frecuencia . Su gráfica consiste en un conjunto de barras, en la que la base de cada barra representa una clase o intervalo, indicada en el eje horizontal, y la altura por su frecuencia, indicada en el eje vertical. Generalmente las barras se trazan adyacentes una a la otra.
POLÍGONO DE FRECUENCIA
De segmentos de línea que conectan los puntos formados por la intersección del punto medio de clase y la frecuencia de clase absoluta, relativa o porcentual.
PICTOGRAMAS
Es un tipo de representación que se utiliza para variables cualitativas, y que consiste en representar los datos con dibujos alusivos a la estadística estudiada. Los pictogramas son muy expresivos, pero poco precisos.
Hay dos clases de pictogramas:
- Se utiliza un dibujo que representa la variable estadística y ésta se repite tantas veces como haga falta (frecuencia absoluta).
- El dibujo utilizado varía de tamaño dependiendo de su frecuencia; a mayor frecuencia mayor es el dibujo.
El siguiente pictograma representa la evolución del número de hectáreas sembradas de trigo en un país.



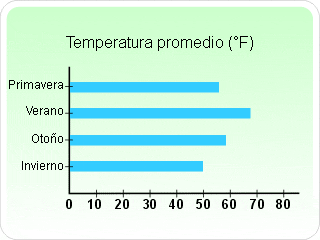




 la frecuencia absoluta del intervalo modal y
la frecuencia absoluta del intervalo modal y  y
y 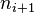 las frecuencias absolutas de los intervalos anterior y posterior, respectivamente, al intervalo modal.
las frecuencias absolutas de los intervalos anterior y posterior, respectivamente, al intervalo modal.


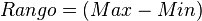


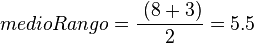



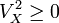
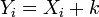
![S_Y^2 = \frac{\sum (Y_i - \bar{Y})^2}{n} = \frac{\sum [(X_i + k) - (\bar{X} + k)]^2}{n} = \frac{\sum (X_i + k - \bar{X} - k)^2}{n} = \frac{\sum (X_i - \bar{X})^2}{n} = S_X^2](https://upload.wikimedia.org/math/8/7/9/8792ad113547be8ff8af2e69a3d6ffbb.png)
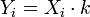
![S_Y^2 = \frac{\sum (Y_i - \bar{Y})^2}{n} = \frac{\sum (X_i \cdot k - \bar{X} \cdot k)^2}{n} = \frac{\sum [k \cdot (X_i - \bar{X})]^2}{n} = \frac{\sum [k^2 \cdot (X_i - \bar{X})^2]}{n} = k^2 \cdot \frac{\sum (X_i - \bar{X})^2}{n} = k^2 \cdot S_X^2](https://upload.wikimedia.org/math/5/e/4/5e434cc6f9ea91ec18ede5b81367553a.png)